Wie fehlerhaft ist eben fertiggestellte Software?
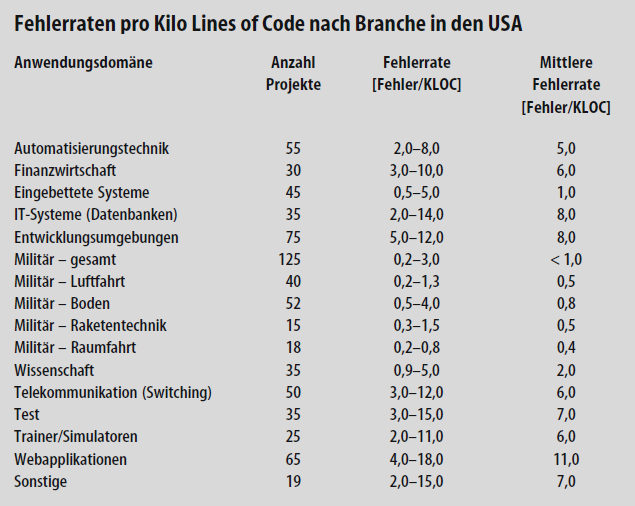
Wer als Auftraggeber vom Entwickler Software ausgeliefert bekommt, wird sich natürlich fragen, wie viele unentdeckte Fehler sie noch enthalten mag.Erstaunlicherweise weiß man das relativ genau, siehe Sneeds Liste unten — die hohe Zahl der Projekte lässt vermuten, dass die genannten Fehlerraten repräsentativ sind. Sie begründen die Faustregel:
soweit man diese Zahl nicht noch branchenspezifisch zu präzisieren weiß.
Zudem hat sich gezeigt, so berichtet Sneed, dass die Kenngröße Bugs/KLOC (= Bugs per 1000 Lines of Code) unabhängig von der Programmiersprache ist, in der der Code geschrieben wurde.
Konsequenzen daraus sind:
- Je mehr der Software-Entwickler von Code-Generatoren Gebrauch gemacht hat, desto fehlerfreier wird sein Produkt sein (es ist dann ja weniger Code zu schreiben).
- Wer den Sourcecode einsehbar hat und zudem per Bug-Tracking-System Buch darüber führt, wie viele Fehler User und Tester (ohne Mithilfe der Entwickler) im Produkt schon gefunden haben,
der wird zu jeder Zeit in der Lage sein, vernünftig abzuschätzen, wie viele Fehler darin immer noch unentdeckt enthalten sein könnten.
Nur etwa 5% aller Fehler lassen sich durch Code-Scanner finden (siehe die Coverty Scan Reports
für Open Source Software).
Sneed schreibt weiter: Jeder Entwicklungsbetrieb sollte in der Lage sein, die Fehlerstatistiken aus früheren Projekten auf neue Projekte zu projizieren. Man sollte davon ausgehen, dass bis zu 80% der Fehler durch die Tester mit vertretbaren Aufwand gefunden werden sollten. So wurden beispielsweise im GEOS-Projekt in den früheren Entwicklungsphasen 72% aller Fehler von den Testern gemeldet, später dann — als Folge der Testautomatisierung — mehr als 85% bei nur einem Drittel des früheren Testaufwands [Sneed, Baumgartner, Seidl: Der Systemtest Requirements-based Testing. Hanser 2008, S 16].
stw4308FTS — Fehler . Tester . Sneed — News?
Mehr + B G E + S H A + More